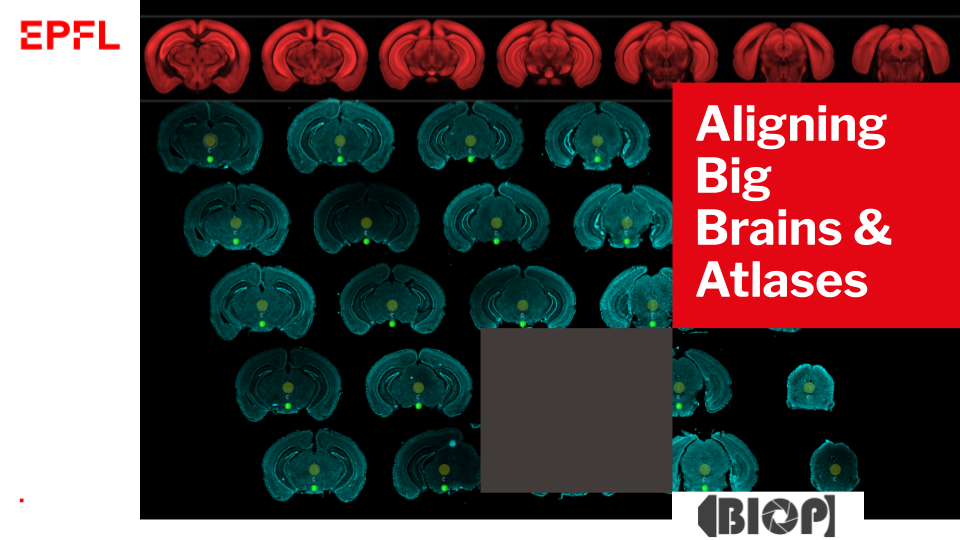
Documentation of the Aligning Big Brains & Atlases Fiji plugin.
View the Project on GitHub BIOP/ijp-imagetoatlas